第10次课-transformer
本次课程主要就是看一篇论文 Attention is All you Need.
Transformer 实际上就是一个带self-attention的seq2seq,包括encoder和decoder两部分,但是它是第一个完全依赖于 Self-Attention 来计算其输入和输出表示的模型,而不使用 RNN 或 CNN。Transformer 由且仅由 self-Attention 和 Feed Forward Neural Network 组成。Transformer中包括了编码器和解码器各 6 层,总共 12 层的 Encoder-Decoder。
RNN的一个缺点是很难并行化。因为RNN本身就是一个序列的概念,计算是顺序进行的(如果把 ![[公式]](/img/loading.gif)
而self-attention的好处是RNN可以做的事情都可以用self-attention来做,可以处理较长的句,并且self-attention还可以并行。
Transformer的结构
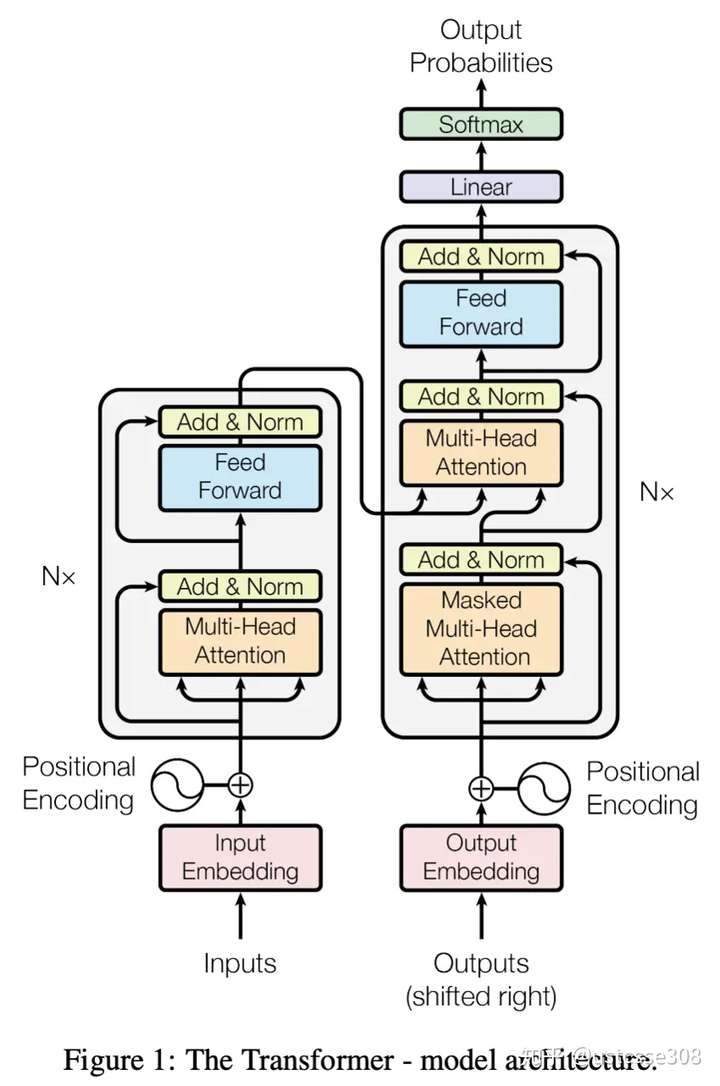
Transformer 采用的也是经典的 Encoder 和 Decoder 架构。
Encoder 的结构由 Multi-Head Self-Attention 和 position-wise feed-forward network 组成,Encoder 的输入由 Input Embedding 和 Positional Embedding 求和组成。
Decoder 的结构由 Masked Multi-Head Self-Attention,Multi-Head Self-Attention 和 position-wise feed-forward network 组成。
Decoder 的初始输入由 Output Embedding 和 Positional Embedding 求和得到。
和 Encoder 相似,Decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
- Multi-Head Self-Attention
- Multi-Head Context-Attention
- Position-Wise Feed-Forward Network
上面三个部分都有残差连接 (redidual connection),然后接 Layer Normalization。 Decoder 多了个 Multi-Head Context-Attention,如果理解了 Multi-Head Self-Attention,这个也比较容易理解。
Encoder 由 6 个相同的层组成,每个层包含 2 个部分:
- Multi-Head Self-Attention
- Position-Wise Feed-Forward Network (全连接层)
两个部分都有残差连接 (redidual connection),然后接一个 Layer Normalization。
Encoder 的输入由 Input Embedding 和 Positional Embedding 求和组成。
什么是 Layer Normalization 呢
为什么transformer要加入positional embedding呢?
因为attention的天涯若比邻,失去了句子中词语的位置信息。
解码过程
Mask
mask就是对某些值进行掩盖,使其不产生效果。
Transformer 模型里面涉及两种 Mask。分别是 Padding Mask 和 Sequence Mask。
其中,Padding Mask 在所有的 Scaled Dot-Product Attention 里面都需要用到,而 Sequence Mask 只有在 Decoder 的 Self-Attention 里面用到。
1、padding mask:处理非定长序列,区分padding和非padding部分,如在RNN等模型和Attention机制中的应用等
2、sequence mask:防止标签泄露,如:Transformer decoder中的mask矩阵,BERT中的[Mask]位,XLNet中的mask矩阵等
所以, Scaled Dot-Product Attention 的 forward 方法里面的参数 attn_mask 在不同的地方会有不同的含义。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!