第5课-神经网络基础-2 词向量-1
01:15:30开始词向量
词向量的非常重要。
个性 用 1 * 5的向量表示.
X空间映射到Y空间是什么意思?

X空间的一个元素,用Y空间的元素(Y空间的一个向量)来描述。
使用向量表示有什么好处呢?
- 一方面是因为这样简单直观;另一方面大概是因为计算机处理向量很在行。
- 在图像处理中,一般也将图转换为向量。图片可以方便地将它的像素矩阵转换为向量;
- 人的性格相似度比较,相似函数比较常用的是cosine similarity
- 我们可以将人和事物表示为代数向量(计算机容易处理);
- 我们可以很容易地计算出相似的向量之间的相互关系。
2个句子的相似性计算
1.分词2.列出所有的词。3.计算词频。4.写出词频向量。5.用数学相应函数计算
早期表示词的方法:one-hot
在NLP中,譬如一个系统中有10000个词汇,每个词汇有一个序号,通常是字典序,那么每个词汇使用10000*1的向量表示,这个向量在词汇对应的序号的位置上是1,其他的位置上全部是0。
它的问题:
- 首先,是向量维度很大;
- 其次,仅仅与词汇在系统中的位置相关的编码方法没有办法表达词汇的意义
那么怎么使用向量来处理文本,以及文本/词怎么转换为向量呢?
表示词的方法:word embedding(将单词按照含义进行编码成向量)
1.什么是word embedding?
Embedding在数学上表示一个函数 f: X -> Y,对于word embedding,就是将单词word映射到另外一个空间,可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中。 word embedding,就是找到一个函数,生成在一个新的空间上的表达,实际上就是word representation。
2.为什么要进行这样的embedding呢?
主要是为了表示词的含义,词汇之间的内在联系。meaning,可以把最终的Y空间想成是一些特征,通过这些特征来描述一个词。如果映射得当,像上面的图,在二维空间中,run和chase的位置比较接近,也就意味着它们两个对应的向量比较像;或者反过来说,如果我们能够得到词的合适的向量表示,词义相近的词向量表示相近,就能较好地体现它们的语义。
word2vec中,Y空间大概有300维。也就是说,每个词使用300*1向量表示,这样,相比于One-hot,维度大大缩减。(word2vec是word embedding所在论文附带的word2vec的工具包)
eg:吴恩达老师课中的例子:
利用Word embeddings可以找到”“Man”与“Woman”的关系类比于“King”与“Queen”的关系“的对应类比关系。具体来说就是用词的向量相减。
下面这个相似函数不理解?
根据等式 ![[公式]](/img/loading.gif)
利用相似函数,计算与
另外,可以使用cosine similarity计算各个词之间的相似性:
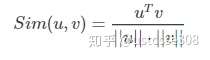
[还可以计算Euclidian distance来比较相似性,即
eg:看一个真实的词king的词嵌入(就是个向量)

学习word2vec来讨论如何获得这些词向量。
实现word embedding就是为每个单词构造一组特征。
向量空间模型 (VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。
1.假设:上下文相似的词,其语义也相似,即,通过使用一个词周围的词来代表这个词。(1954年)
采用这一假设的研究方法大致分为以下两类:
2.基于计数的方法 (e.g. 潜在语义分析, Glove):
计算某词汇与其邻近词汇在一个大型语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小型且稠密的向量中。
3. 预测方法 (e.g. 神经概率化语言模型,word2vec).
试图直接从某词汇的邻近词汇对其进行预测,在此过程中利用已经学习到的小型且稠密的embedding向量。
4.word2vec
4.1主要内容:
两个算法:
1. skip-grams(SG) 给定目标单词,预测上下文单词
2. Continuous Bag of Words(CBOW),从词袋上下文中预测目标单词
两个训练方法
1. hierarchical softmax
2. negative sampling4.2什么是word2vec
word2vec就是通过使用大量文本,根据词的上下文,使用一个带有单个隐藏层的简单神经网络,这个神经网络并不是用于预测任务,目的只是学习输入层到隐藏层的权重,这些权重实际上就构成了我们试图学习的“词向量”。
4.2.1 eg王菲
隐藏层的结果是词向量。训练结束后,隐藏层这个矩阵中的每一行就是一个单词的词向量。
4.2.2 eg 说明word2vec的工作过程
???
值得注意的是,隐藏层和输出层都没有使用激活函数。也即,这个神经网络学到的是线性关系。这是可以理解的。因为,在神经网络中使用激活函数的目的是增强非线性,但处理词的问题时,我们知道一个词与其上下文是相关的,也就是说输入的上下文几个词也应该是线性相关的。没有了激活函数也就意味着承认了输入的几个上下文词的关系也是呈线性相关的。Tomas Mikolov就发现了如果将DNN模型中的激活函数移除,训练出来的词向量就会成大量线性相关。由于目标是产生输出层中单词的概率,
这就是Word2vec如何学习单词之间的关系,并在此过程中为语料库中的单词产生向量表示。
4.2.3详细讨论下word2vec
最简单的情况,给定一个上下文单词,预测一个目标单词。
多词上下文(太短的上下文表示的意义不够)
词向量训练是给定句子中间的特定单词,神经网络将告诉我们词表中每个单词成为我们选择的“nearby word”的可能性。“nearby”意味着算法有一个“窗口大小”参数。典型的窗口大小可能是5,意味着输入单词后面5个词,前面5个词(总共10个字)
CBOW模型的训练输入是某一个特征词的上下文(context)相关的词对应的词向量,而输出就是这特定的一个词(目标单词target)的词向量
上面是神经网络语言模型中的。word2vec中不是这么实现的.
两个训练方法
- hierarchical softmax(哈夫曼树?)
- negative sampling
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!